19. april 2023
Mange virksomheder oplever, at deres datagrundlag bliver større og mere komplekst. Flere produkter, flere kanaler, flere services og flere kundesegmenter der skal serviceres øger alt sammen behovet for god datagovernance, og her kommer dataorganisationen ind i billedet.
Når behovet for at arbejde med stadigt flere og mere komplekse data konstant trænger sig på, kigger flere virksomheder sig om efter muligheder for at blive bedre til at udnytte disse data i værdiskabende sammenhænge.
Og her kommer begrebet om "dataorganisationen" ind i billedet. Dataorganisationen er sat i verden for at sikre, at virksomhedens arbejde med data skaber værdi.
Dataorganisationen består af en eller flere personer der ved hjælp af analyser, håndtering af større datamængder og anvendelse af fx produktdata på tværs af digitale platforme, formår at skabe øget interesse for organisationens produkter, hvilket i sidste ende fører til øget omsætning.
Et øget behov for professionalisering i arbejdet med data
I takt med at vi får adgang til flere data, og at disse data skal publiceres på stadig flere kanaler, får vi også et øget behov for at en professionel omgang med data.
Udviklingen af en dataorganisation kan derfor også betragtes som en udvikling, der aldrig stopper. Dataorganisationen er sat i verden for at understøtte virksomhedens behov, og skaleringen af dataorganisationen vil derfor ofte være et centralt strategisk indsatsområde, der – hvis det gøres rigtigt – leverer en høj ROI på investeringer i datarelaterede teknologier og processer.
Den effektive dataorganisation finder ikke bare muligheder for automatisering og forbedring af dataprocesser, men også helt nye måder at anvende data på.
I dette indlæg tager vi begrebet ”dataorganisation” under behandling, når vi stiller spørgsmålene:
- Hvad er en ”dataorganisation”, og hvorfor bør du have en?
- Hvem udgør dataorganisationen?
- Hvilke roller har medlemmerne af en dataorganisation?
- Hvad kræver den gode implementering af en dataorganisation i en virksomhed?

Hvad er en dataorganisation, og hvorfor bør du have en?
De fleste af de virksomheder som vi til dagligt arbejder sammen med, og som oplever en stigning i mængden og kompleksiteten af deres data, går alle med et ønske om, at bliver bedre til at anvende deres data i værdiskabende sammenhænge.
For disse virksomheder er processer og teknologier der understøtter anskaffelse, berigelse, strukturering og publisering af data centrale for den værdiskabelse, der finder sted. Med PIM-systemet som omdrejningspunkt er produktdata det råstof, vi og vores kunder fokuserer på.
De mest ambitiøse virksomheder overlader ikke arbejdet med data til tilfældigheder (eller tilfældige kolleger), men opretter med fuldt overlæg en såkaldt dataorganisation.
Dataorganisationen sikrer værdiskabelse gennem anvendelse af data
Denne dataorganisation er sat i verden for at varetage arbejdet med at gøre de rå data til et værdiskabende aktiv. Det kan gøres ved at:
- sikre korrekt adgang til data
- sikre mulighed for nem berigelse af data
- sikre nem adgang til data (fx via veltilrettelagte API’er)
- og meget, meget mere…
Størrelsen og strukturen på en dataorganisation vil til enhver tid være afhængig af virksomhedens størrelse, den samlede mængde af data (fx produktdata) og virksomhedens nuværende og fremtidige tekniske setup.
Opbyg en dataorganisation ved at fokusere på disse basiskrav
Hvis udviklingen og implementeringen af en velfungerende dataorganisation skal være tryg, og øge chancen for at indfri virksomhedens målsætninger, oplever vi, at der eksisterer en række basiskrav, der kræver et kontinuerligt fokus.
Disse basiskrav er forholdsvis generiske, og vil være gældende for alle virksomheder, som arbejder med data. Basiskravene kan direkte omformuleres til funktioner eller roller, der er nødvendige for oprettelsen og implementeringen af en dataorganisation samt de basale dataprocesser, som dataorganisationen ejer.
Vi vil i de kommende afsnit beskæftige os med disse basisfunktioner og komme med forslag til deres forankring i den effektive dataorganisation.

Dataorganisationens fokusområder
Overordnet set har dataorganisationen ansvaret for to særskilte dimensioner af arbejdet med virksomhedens data, som vi her har valgt at dele op som følger:
- Dimension 1: ”Indefra-ud” – de interne data, dataorganisationen er ansvarlige for
- Dimension 2: ”Udefra-ind” – de ”endpoints” som data slutteligt skal fordeles til/i
Arbejdet med disse dimensioner dækker naturligvis over en række forskellige aktiviteter der både kan have teknisk og forretningsmæssig karakter.
”Indefra-ud” – virksomhedens data-aktiver
Indefra-ud-dimensionen retter fokus imod de interne datasæt, som er nødvendige for driften af det systemlandskab, der udgør virksomhedens operationelle rygrad.
Her møder vi ofte datasæt for ERP, logistik, prissætning, rabathåndtering mv., der vil være at finde i stort set alle handelsvirksomheder i dag.
Disse datasæt medvirker bl.a. til at gøre en vare ”salgbar”, og er det råstof, som virksomheden i højere eller mindre grad kan være dygtige til at raffinere.
”Udefra-ind” – virksomhedens kunder, kanaler og konkurrenter
Udefra-ind-dimensionen retter vores fokus imod kundernes adfærd og de mere brugsorienterede behov der findes i de kanaler, hvor en vare afsættes.
Her møder vi som regel datasæt, som understøtter søgning, sammenligning, navigation, brugergenereret data i forskellig afskygning, copywriting, SEO-optimering mv.
Disse datasæt medvirker til at gøre varen ”findbar” og ”købbar”, og er kritiske for den gode brugeroplevelse, hvilket i sidste ende er det konkurrenceparameter, der fører til et salg.
Ideelt set skal virksomheder der ønsker effektive dataorganisationer sikre, at begge disse dimensioner varetages.

Dataorganisationens roller og funktionsområder
I praksis er en af de diskussioner virksomheder har med sig selv, når de opretter en dataorganisation, hvorvidt det giver mening at have ”rene” fuldtidskompetencer i dataorganisationen eller ej.
Uanset om dataorganisation består af hel- eller deltidskompetencer, eller en blanding heraf, er de roller som disse kompetenceprofiler skal udfylde dog altid nogenlunde generiske, hvorfor denne diskussion sjældent er så væsentlig for dataorganisationens ansvarsområde, som den er for virksomhedens interne modus operandi og planlægning af den generelle drift.
Roller i dataorganisationen
For de fleste virksomheder gør det sig derfor gældende, at den effektive dataorganisation består af følgende roller (der i øvrigt typisk har et fokus på indefra-ud dimensionen):
- Data-ejer (data owner)
- Definition: En Data owner/”Dataejer” er person, der træffer beslutninger såsom:
- Hvem der har ret til at få adgang til data?
- Hvem der må redigere i data?
- Hvorledes (og hvor) må data bruges?
- Data-ejere arbejder ikke nødvendigvis med data hver dag, men er ansvarlige for at overvåge og beskytte et eller flere datadomæner (dette kan fx være ERP masterdata, leverandørdata, CRM-data, billeder og videoer).
- Definition: En Data owner/”Dataejer” er person, der træffer beslutninger såsom:
- Analytisk dataekspert (Data scientist)
- En analytisk dataekspert er en funktion, som:
- Har de tekniske færdigheder til at løse komplekse problemer i forhold til fx skabelse, strukturering eller rensning af data
- Har nysgerrigheden til at udforske, hvilke problemer der skal - og kan - løses.
- Analytiske dataeksperter er i deres reneste form dels matematikere, dels dataloger og dels trendspottere (”forretningsnære”).
- En analytisk dataekspert er en funktion, som:
- Data-supporter (Data steward)
- Data-supporterens rolle er primært at støtte brugerfællesskabet i den datadrevne organisation
- Data-supporteren er således ansvarlig for at indsamle, organisere og evaluere data-opgaver og problemer med data, hvorefter denne kommer med løsningsforslag til organisationen.
- Data-arkitekt (Data architect)
- En ”Data Arkitekt” er en it-professionel, der er ansvarlig for at definere de politikker, procedurer, modeller og teknologier, der skal bruges til at indsamle, organisere, opbevare og tilgå virksomhedsoplysninger
- Data arkitekter fokuserer på business intelligence-relationer samt datapolitikker på højt niveau.
- Data-partner (Data partner)
- En data-partner er en organisation, der leverer data og/eller tjenester i henhold til virksomhedens ”Masterdataaftale(r)”.
Som supplement til disse roller er der et behov for en funktion, som har fokus udefra-ind:
- Kanal-ejer
- En Kanal-ejer har ansvaret for at sikre, at salgskanalen til enhver tid understøtter alle brugermæssige behov hos kanalens brugere (kunderne) og effektive købsrejser.
- Content-skabere
- En content-skaber et typisk en intern funktion, som skaber indhold til de kanaler, hvor det behøves. Det er fx copywriters og fotografer.
Det er vigtigt at understrege, at alle disse funktioner sagtens kan være kombineret i en og samme person. Det vil som regel være tilfældet i mindre virksomheder, der befinder sig tidligt i deres digitale rejse. I større organisationer vil en ung dataorganisation typisk også bære præg af, at en enkelt/få personer varetager flere roller.
Husk at revidere jeres roller og rollesbeskrivelser
Men efterhånden som virksomheden vokser og skalerer, og der kommer flere kanaler, flere data/produkter og flere datadomæner bør der være fokus på at skabe en organisation, hvor funktionerne forankres i ”rene” roller. Typisk vil arbejdsbyrden i forbindelse med varetagelse af de individuelle ansvarsområder presse dataorganisationen i denne retning helt naturligt.

Implementering af en dataorganisation – hvad kræver det?
For at de forskellige rollebeskrivelser ikke bare bliver fine titler, som I hænger om nakken på folk i organisationen, peger alle vores erfaringer på, at en god implementering af de centrale principper er afgørende for jeres succes.
I vores optik kræver den gode implementering af dataorganisationen:
- Et sundt systemlandskab og en dertilhørende værktøjskasse, der understøtter den nødvendige datahåndtering for de forskellige domæner og funktioner, der blev beskrevet i forrige afsnit
- Logiske funktions- og rollebeskrivelser, der giver mening for personerne i organisationen
- Trænings- og onboardingprogrammer, som sikrer, at personerne bag funktionerne har de nødvendige faglige forudsætninger og den nødvendige forståelse for helheden, til at de kan løfte de påtænkte opgaver
- Tilpassede workflows og processer, som sikrer effektive arbejdsgange på tværs af de forskellige funktioner, og som giver organisationen mulighed for løbende styring og tilpasning.
En succesfuld implementering hviler derfor på en indsigt og indsats fra hele organisationen.
Som med enhver god forandringsproces er ledelsens opbakning kritisk for den øvrige organisations evne til at løfte den fælles opgave. Det gælder både med henblik på ledelsens allokering af ressourcer, men også i forhold til den energi og den opbakning medarbejderne oplever.
Centrale redskaber i den gode implementering
Kigger vi nærmere på de fire punkter på listen herover, er det relevant at uddybe deres omfang og indflydelse mere præcist:
Fokusområde #1 - Systemlandskab og værktøjskasse
Vi har allerede kortlagt, at disse roller er nødvendige for god datagovernance og for, at den sunde dataorganisation kan fungere.
Men hvad med jeres systemlandskab – understøtter det også de forskellige funktioners daglige arbejde med data?
Standardisering af jeres tech-stack hjælper dataorganisationen i gang
Vi har igennem tiden set mange eksempler på systemlandskaber, hvor en sammenblanding af datadomæner har ført til, at virksomheden ligger inde med en stor teknisk gæld.
Dette opstår typisk som følge af, at it-systemer som aldrig har været tiltænkt håndtering af mere end et enkelt domæne, af forskellige årsager er blevet gjort til ansvarlig for to, tre eller flere domæner. Det klassiske eksempel er ERP-systemet, som er blevet udbygget med funktionalitet og felter til at håndtere kanaldata, eller DAM-systemet, som bruges til at håndtere produktdata og priser.
Resultatet er altid det samme; dyre, komplicerede og skrøbelige ”her-og-nu”-løsninger på nogle problemer, der dybest set kun fortsætter med at udvikle sig. Konsekvensen af dårlige investeringer bliver, at virksomheder ender med dyre, statiske systemer, hvor al fleksibilitet er pillet ud af arkitekturen.
Lav et roadmap for jeres samlede systemlandskab
Hvis domænesammenblandingen er for stor, er der risiko for, at dette bliver en benspænd for effektiviteten i arbejdet med data for dataorganisationens forskellige medlemmer. Derved opnår virksomhedens heller aldrig de reelle fordele, som dataorganisationen vil være i stand til at skabe.
Et sundt systemlandskab har en tydeligt defineret arkitektur samt et teknisk roadmap, der baner vejen for en bæredygtig og fremadskuende udvikling af virksomhedens tekniske fundmant.

Fokusområde #2 - Logiske funktionsbeskrivelser
Som skrevet betragter vi de forskellige funktioner som generiske, og dermed for at være anvendelige, i alle virksomheder, som håndterer data.
De logiske funktionsbeskrivelser kortlægger rollernes ansvarsområder, og fungerer som afsæt for dialog omkring dataorganisationens daglige virke.
Den helt præcise funktionsbeskrivelse bør dog altid tilpasses hver enkelt virksomhed, da disse som regel bliver meget specifikke, når det eksisterende systemlandskab medregnes. Der er sjældent er to virksomheder, der arbejder med nøjagtigt de samme systemer, i den nøjagtigt samme arkitektur.
Analysér jeres arbejdsgange og find optimeringsmulighederne
Best practice er derfor også, at virksomheder laver tilpassede funktionsbeskrivelser, der passer til det domæne og det systemlandskab, virksomheden begår sig i.
Udbyder virksomheden for eksempel et bredt sortiment af meget forskellige produkter, eller sælger virksomheden et mix af produkter af brandede produkter, der købes fra en leverandør eller grossist sammen med en række own-brand-produkter, som man selv ejer størstedelen af data-processen for, vil disse funktionsbeskrivelser være meget specifikke.
Her skal der både tages højde for kompleksiteter i import af data fra mange kilder, samtidigt med, at berigelse og udstilling af data skal tilgodese de korrekte brands i de korrekte kontekster således, at der ikke opstår forvirring omkring copyright, brand-ejerskab og evt. compliance.

Fokusområde #3 - Trænings- og onboardingprogrammer
I forlængelse af funktionsbeskrivelserne i pkt. 2, er trænings- og onboardingprogrammerne redskaber til at udbrede ”best practice” omkring den konkrete udførelse af dataarbejdet.
Uddannelses- og træningsmaterialet er desuden et godt sted at fastholde viden, så den ikke forlader virksomheden.
For nogle virksomheder vil der være system- og metodefrihed, imens størstedelen af virksomheder dog håndhæver en eller anden politik med hensyn til hvilke systemer og metoder, der forventes at den enkelte medarbejder benytter sig af.
Vælg den uddannelsesmetode, der passer jeres organisation bedst
Onboardingprogrammer og træningsmateriale er ikke nye koncepter, og der findes således også flere velkendte formater, man kan benytte sig af:
- Trykt materiale
- Video-træning
- Sidemands-oplæring
- Kursusdage
- Case-træning
- Virtuel træning
Der findes (os bekendt) ingen silver bullet, når det kommer til at vælge det ”bedst egnede” uddannelsesformat.
Vælger man fx sidemandsoplæringen, er det vores anbefaling, at man baserer uddannelsesforløbet på trykt materiale, så der sikres en rød tråd i oplæringen.
Afholder man interne kursusdage (evt. med eksterne undervisere), er det væsentligt, at tempo, tone og indhold passer til kursisternes temperament – ellers spilder man hurtigt dyrebar tid, og risikerer at skabe frustrationer i teamet.
Man kan vælge at gøre trænings- og onboardingprogrammerne meget specifikke og inkludere detaljer om helt konkrete systemfeatures. Dette vil som regel resultere i nem onboarding, men det medfører ofte mere administration i form af vedligehold af undervisningsmaterialet, hver gang man har lavet ændring i opsætningen af et system.

Fokusområde #4 - Workflows og processer
I arbejdet med data starter og slutter alting med effektive processer!
Uanset om man vælger en monolitisk orienteret tilgang til sin it-arkitektur, hvor flere funktioner løses i/af den samme platform, eller man vælger en best of breed tilgang i en microservice-arkitektur, så er der en proces, der går på tværs af organisationen og af systemlandskabet [MIK: Hvad menes der med dette?].
Vores klare anbefaling er, at I altid starter med at fokusere på det, vi kalder ”den nøgne proces”.
Tænk i procestrin - ikke i softwarespecifikke funktioner
Metoden i ”den nøgne proces”-model hviler på, at I undlader at inddrage jeres systemer/software i jeres analyse, og i stedet fokuserer på de forskellige procestrin, der er imellem de forskellige funktioner i dataorganisationen.
Kort sagt bør I ikke beskrive hvilke knapper, I trykker på eller hvad navngivningen af funktionerne i systemerne er. Fokusér i stedet på den forretningsmæssige funktion – "nogen" skal gøre "noget", før "nogle andre" kan gøre "noget andet". Alt dette gøres indtil en betingelse er opfyldt, og en gevinst realiseres.
Når I anlægger dette fokus, vil I få skabt klarhed over de steder hvor jeres processer og workflows fungerer godt, og ligeså hvor de fungerer dårligt – eller slet ikke. Fungerer processer ikke, bruger man ofte begrebet ”[a] broken process”, der dækker over processer, der er skyld i et uforholdsvist stort tidsspild. Med den nøgne proces-metoden kaster vi lys over, hvad det er, der helt konkret ikke virker, og hvordan vi kan løse problemet.
Workflowanalysen viser vej
PicoPublish har udviklet et workflowanalyse-format, der skaber fuld klarhed over jeres processers tilstand, og som afslører alle fejl – og sætter værdi på potentialet i at få processen på skinner igen.
En workflowanalyse kan typisk afvikles på en eller to dage. Typisk vil analysen hvile på samtaler med og observation af nøglemedarbejdere i jeres dataorganisation. Ved at kortlægge alle procestrin bliver det muligt at danne et overblik over, hvordan forskellige skjulte arbejdsgange og uhensigtsmæssigheder i overlevering af opgaver, giver anledning til effektivisering.

Opfølgende aktiviteter - Skab overblikket!
På dette tidspunkt i processen er vi nået så langt, at vi har identificeret og beskrevet de forskellige funktioner i dataorganisationen, vi har også fået styr på systemlandskabet og på den mest centrale processer i virksomheden.
Hvordan skaber man så overblik over dataorganisationens funktioner i forhold til de data, som skal håndteres, og som giver os den referenceramme, som organisationen arbejder i til dagligt?
Der findes forskellige måder at gøre dette. Den helt simple metode er at opstille en tabel, der indeholder de data og dataansvarlige, der befinder sig under dataorganisationens paraply.
Tabellen skal opstilles ud fra en logik, som giver mening internt. Det kunne for eksempel være på basis af produktkategorier, hvor tabellen kunne tænkes at have denne udformning:
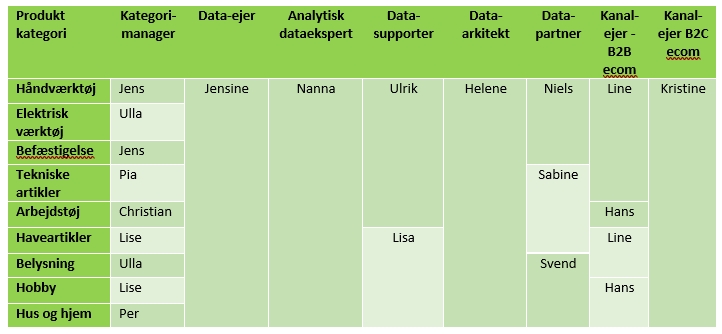
Én ting er at skabe overblikket. En anden ting er dog at operationalisere overblikket på en måde, så det understøtter jeres overordnede mål. For mange PIM-systemer gælder det, at man kan oprette dashboards og workflows, der understøtter automatisering af de processer der er i arbejdet med produktdata.
Et eksempel kunne være "Produkter uden billeder", der kunne synliggøres via et dashboard. Produkterne der er omfattet af disse betingelser - altså manglende billeder - kan derefter automatisk fordeles til de rette ansvarliges opgaveliste i systemet, således at medarbejderen kan fokusere på berigelse, og altså IKKE på identifikation og fejlsøgning.
Hvis man tænker og implementerer dette rigtigt, vil man gå fra et simpelt overblik til reel procesunderstøttelse med et højt potentiale for automatisering af processer og opgavestyring.
Konklusion og checkliste
Opbygning af dataorganisationer tager tid, og det kan være svært at gøre uden hjælp udefra. Vi er typisk for indgroede i vores egne rutiner til, at vi kan se deres (eventuelt skadelige) effekter.
I dette indlæg har vi skitseret den model vi bruger, når vi hjælper virksomheder med at opbygge deres interne dataorganisationer. En af de ønsker vi gentagne gange hører, at virksomheder efterspørger, er eliminering af trivielle arbejdsopgaver og/eller langsommelige, manuelle processer.
Med en workflowanalyse bliver det hurtigt tydeligt hvordan dataorganisationens forskellige roller kan aflaste hinanden, og hvordan arbejde kan helt/delvist automatiseret så hele dataorganisationen bliver aflastet. Som med meget anden automatisering er formålet ofte at frigøre tid til vigtige kerneopgaver blandt medlemmerne i teamet.
Afslutningsvis vil vi her opsummere de forhold, vi mener er essentielle at fokusere på, når I skal opbygge en effektiv dataorganisation.
For brugervenlighedens skyld har vi lavet vores opsummeringen som en checkliste, som I kan bruge til at vurdere, hvor behovet er størst for at sætte ind i jeres virksomhed.
Checkliste for opbygning af den gode dataorganisation
Hent vores checkliste HER.
{kind=link}
